Here’s how the story often goes: you have this process at your company that absolutely has to be done — processing claims, triaging requests, reviewing documents — that kind of task that requires a human, but everyone involved would rather spend their time self-inflicting mild electric shocks as in that famous experiment about boredom rather than actually doing it, and you know that if you could just take it off people’s plates, the whole team would be better for it and get you a nice present. So you think “but wait, AI is all over the place today” and you decide to give it a try.
You build a prototype, or you hire someone to build it, begin using it and it seems to work great — the pipeline reads an email, pulls out the right fields, cross-references a database, and spits out a clean report… until it suddenly, miserably, awkwardly fails. And you stop there, wondering if all that talk about AI bubble is real or not, if all these machines are ever gonna replace us and stuff like that, but you’re missing the point: nobody remembered to find an answer to a couple of pretty important questions regarding AI models — how often does this thing get it wrong, and how would we even know?
These are actually very well-known questions in machine learning, and people have been answering them for decades. But what makes automation pipelines nastier is that you’re not evaluating a single model anymore. You’re evaluating a chain of stages where AI inferences, data transformations, and good old deterministic code all blend together into a final result — and that result doesn’t map neatly to any one model’s prediction. It’s the product of everything working in concert.
On top of that, the bar isn’t abstract. These pipelines are replacing tasks that humans used to do, tasks where people made judgment calls and where the organization had a sense, however informal, of how often those calls were right. Now you’ve handed that job to a machine, and the real question is: is it at least as reliable as the person was? To answer that, you need more than a working prototype. You need a strategy for measuring what your pipeline actually gets right, what it gets wrong, and how confident you can be in those numbers.
What you’re actually automating (and why it’s messy)#
Let’s take a step back and look at what we’re actually dealing with. When a company decides to automate one of these processes, the task in question is almost never a clean, well-documented procedure. It’s the kind of thing that lived in someone’s head — or worse, in the collective intuition of an entire team. The inputs are emails, PDFs, scanned forms, spreadsheets that someone updates manually, maybe a phone call that gets summarized in a sticky note. The “workflow” was never really a workflow. It was people figuring it out as they went, drawing from experience and domain knowledge that nobody ever bothered to write down because, well, it just worked.
This is the first thing that catches most people off guard: before you can automate a process, you have to formalize it. And formalization is a project in itself. It means sitting down with domain experts, mapping out every decision point, understanding what information goes where and why, and translating all of that into something a machine can follow. Part of our job, honestly, is doing exactly this — helping clients turn tribal knowledge into a concrete workflow before a single line of code gets written.
Once you do have that workflow mapped out, here’s what the actual pipeline looks like: it’s not one AI model doing one thing. It’s a chain of stages — some of them are AI inferences (reading a document, classifying a request, extracting structured data), some are plain data transformations (reformatting, enriching, cross-referencing against a database), and some are pure deterministic business logic (if this field is above threshold X, route it here). The final output is the product of all these stages working together, and any one of them can introduce errors that cascade downstream.
Now here’s where evaluation gets really tricky. In a traditional machine learning setup, you have a model, you have a test dataset, you run predictions, you compare them to ground truth. Simple enough. But when the task was never formalized before — when it was just Maria from accounting who “knew how to handle these” — there is no test dataset. There’s no neatly labeled collection of inputs and expected outputs sitting in a folder somewhere. The ground truth has to be built from scratch, and building it means going back to those same domain experts and asking them to do the thing they’ve always done, except this time they have to write down exactly what the right answer is and why.
This is the reality of pipeline automation: it’s not just a technical challenge, it’s an organizational one. And it sets the stage for why evaluating these systems is fundamentally different from evaluating a single model.
Why traditional eval solves a different problem — and what we do about it#
That traditional evaluation loop — one model, one prediction, one score — has excellent tools built around it. Platforms that help you manage prompts, run A/B tests, track scores over time. They work great because the problem is well-defined: how good is this model at this task? But as we just saw, in a pipeline the result you need to judge doesn’t map to any single model’s prediction. It’s the product of all those stages working in sequence, and that clean loop just doesn’t fit anymore.
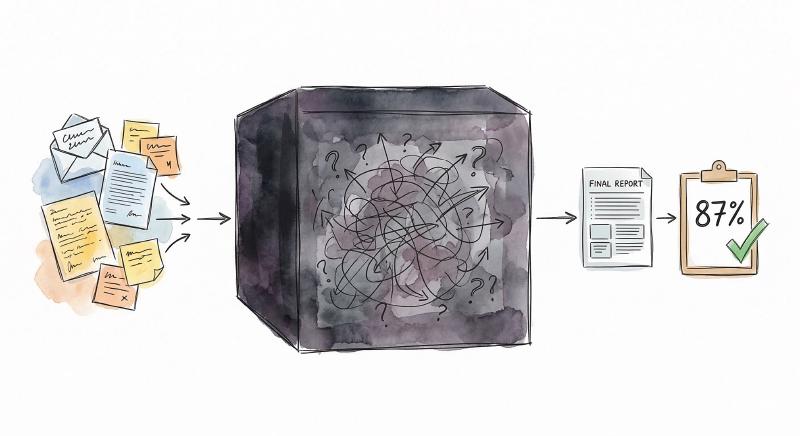
Which leaves you with two options, and neither one is comfortable on its own. The first is to treat the whole pipeline as a blackbox: feed it real inputs, look at what comes out the other end, and compare that to what should have come out. This gives you a real, actionable number — your pipeline gets it right 87% of the time, or 62%, or whatever it turns out to be. That’s genuinely valuable. But when that number drops, the blackbox can’t tell you why. Was it the entity extraction that misfired? The classification? A flawed routing rule? You just know something went wrong somewhere.
The second option is to evaluate every stage independently — build a dedicated test set for each one. Sounds rigorous, until you think about what that means in practice. Most of these intermediate stages represent tasks that never existed as discrete human activities. Take incident triage: a human operator reads a report and routes it to the right department. That’s one fluid judgment call. But in the pipeline, it’s been decomposed into extract entities, classify severity, match department rules, format the output. Nobody ever sat down and did “entity extraction from incident reports” as a standalone job — there’s no historical data for what the correct output of that step looks like. You’d have to manufacture ground truth for tasks that were never tasks, and that’s a massive investment with questionable returns.
So what do we actually do? We start with the blackbox, because the final output is something a human used to produce — building ground truth for it is realistic. We compare the pipeline’s results against those expected outputs field by field: is the extracted name correct? Is the category right? Is the amount within tolerance? Each field gets its own score, and the aggregate gives you a confidence number you can work with. We built an internal evaluation framework around exactly this approach — one that can score the result of any stage, not just raw model outputs, against structured expected results.
The honest takeaway: you get a measurable confidence score, you can ship with eyes open, and you accept that pinpointing exactly where failures originate is something you refine progressively. Which, as it turns out, is exactly how the next phase works.
From blackbox to precision: the evolutionary path#
Once your pipeline is live and you have that blackbox confidence score, something interesting starts to happen: you begin collecting data. Every input that goes through the system, every output it produces, every intermediate result along the way — it all becomes material you can analyze. And this is where the real optimization begins, not from theory, but from evidence.
The first thing you do is look at where errors cluster. When the pipeline gets something wrong, you trace back through the stages and start noticing patterns. Maybe the document parser handles invoices perfectly but struggles with handwritten notes. Maybe the classifier is solid on common categories but falls apart on edge cases that represent 5% of the volume — and 40% of the errors. You don’t need to evaluate everything equally. You need to find the stages that hurt the most and focus there.
Building evaluation sets for those critical stages becomes realistic now, because you’re not starting from nothing anymore. You have real inputs and outputs flowing through the system, and you can cache intermediate results for review. A domain expert can look at fifty examples of what the entity extraction step produced and flag the ones that are wrong — and just like that, you have a ground truth dataset for a task that didn’t exist six months ago. It’s not a theoretical exercise anymore, it’s curation driven by actual production data.
This is also where the economics of AI models get interesting. Your pipeline might be running on a large, expensive foundation model because it needed broad capabilities at launch. But once you’ve identified a specific stage that just needs to do one thing well — classify document types, extract dates, detect language — you can fine-tune a small, focused model on the curated data you’ve been collecting. It does that one job faster, cheaper, and often more reliably than the general-purpose model it replaces.
None of this happens overnight. It’s a months-long journey of incremental improvements, where each cycle makes the pipeline a little smarter, a little more efficient, and a little easier to trust. The key insight is that you’re not guessing where to improve — you’re letting the data from your running system tell you. The blackbox gave you a starting point, and now you’re methodically opening it up, one stage at a time.
What this means if you’re making the call#
If you’ve read this far, I hope I’ve managed to convey my point of view from the other side: “let’s add AI to this” has no silver bullet solution. Setting up a reliable automation pipeline is a deliberate engineering engagement — one that involves understanding the process deeply before touching any code, building the infrastructure to run and evaluate it, and committing to refine it over time. And this doesn’t change even as models get better and cheaper — because the point was never about how reliable a single model can be. It’s about confidently taking ownership of what you deliver to your customers or your internal processes, without having to trust gut feelings. This is what industry has done since forever: measure things reliably and unambiguously. AI is not an exception.
Part of what we do is exactly this: we sit down with clients, help them map out the workflow from their domain knowledge, figure out where automation makes sense and where it doesn’t, and then build the pipeline with evaluation baked in from day one. It’s not just about making the AI work — it’s about integrating it with existing systems, making sure the people who rely on the output can trust it, and having a plan for when things go wrong. Because things will go wrong, and the difference between a good automation and a bad one is whether you find out before or after it matters.
This kind of work takes time. We’re talking months of iterative development, close collaboration between domain experts and engineers, rounds of evaluation and refinement. It’s not a product you install, it’s a partnership you invest in. But the payoff is real: measurable error rates that product teams can reason about, data-driven improvements that compound over time, and a system that gets more reliable the longer it runs.
You don’t need to understand every technical detail we covered here. But if you’re the one making the call on whether to pursue this kind of project, you now know what questions to ask your technical team — and more importantly, what answers to expect. That’s the best starting point there is.